
AI is generating code faster than most testing infrastructure can validate it. And that gap shows up in flaky suites, missed defects, inconsistent test coverage, and mobile releases that ship with fingers crossed rather than data-backed confidence.
In a recent Sauce Labs webinar, The High-Velocity Roadmap: Building Mobile Release Confidence, Sauce Labs mobile testing experts Parth Patel and Ashwini Sathe dug into what’s blocking engineering and QA teams — and what it takes to get unstuck. The conversation drew on findings from the 2026 State of Mobile App Quality report, which surveyed hundreds of engineering and QA leaders on their biggest quality challenges. What they found: 53% of leaders identified scaling test automation as their No. 1 problem, and nearly half said insufficient coverage was preventing them from catching critical defects before they reached users.
Where most teams are stuck
Have you honestly assessed where your organization lands on the automation maturity curve?

Stage one is manual-only testing: exploratory, ad hoc, and heavily dependent on individual testers. It works for small teams … until it doesn’t. Add a second platform or accelerate your release cadence, and the obvious bottleneck becomes human bandwidth.
Stage two — limited automation — is where 49% of teams are currently stuck. Frameworks get adopted and scripts get written, but then maintenance debt quietly overtakes coverage gains. Device fragmentation accelerates the problem. New iOS and Android versions arrive constantly, screen sizes multiply, various hardware configurations cause unexpected performance issues, and the test suite starts returning results that nobody trusts. Here, teams often waste time and money testing in the wrong places.
Stage three, automation at scale, represents what Parth described as elite DORA-level performance: CI integration, parallel execution, real devices in the cloud, and coverage that scales with developer output. The breakthrough that makes this work is persistent device sessions — reserving a device for an entire test suite run, inspecting live failures without digging through logs, and maintaining accurate results through consistent state. The bottleneck here has evolved beyond infrastructure throughput and coverage velocity into AI-generated code volume outpacing what framework-dependent infrastructure can validate.
And that brings us to stage four, which is where the industry is headed: agentic, autonomous testing. AI agents that don’t just execute tests but write them, interact with real devices, triage failures, and self-heal when the UI changes. Getting there requires infrastructure that agents can actually reach — devices exposed as programmable infrastructure, not locked behind a framework.
The diagnostic question: Which stage is your organization actually in today, and what bottleneck is slowing you down? Misdiagnosing the answer means investing effort in solving the wrong problem. Compounding the challenge, AI coding tools haven’t reduced dev burden — they’ve redistributed it to engineers who previously waited for QA but now own the entire quality loop.
The right infrastructure answer addresses that burden directly, not just test execution speed.
A testing pyramid for how mobile software gets built
The classic testing pyramid was designed for a different era. Beyond managing just code, today’s teams manage costs, speed, and system intelligence simultaneously.
So, we need to reframe the software testing pyramid around economics and frequency. High-frequency, low-cost automated tests form the foundation: These are the safety nets that run on every code push, catching small breaks before they compound. The mid-tier layer moves into production-like validation — accessibility scoring, visual UI regression, app performance under realistic network conditions. Higher up sits complex use case validation using real beta testers, which is intentionally low-frequency because the cost justifies focused investment on the journeys that actually drive revenue.
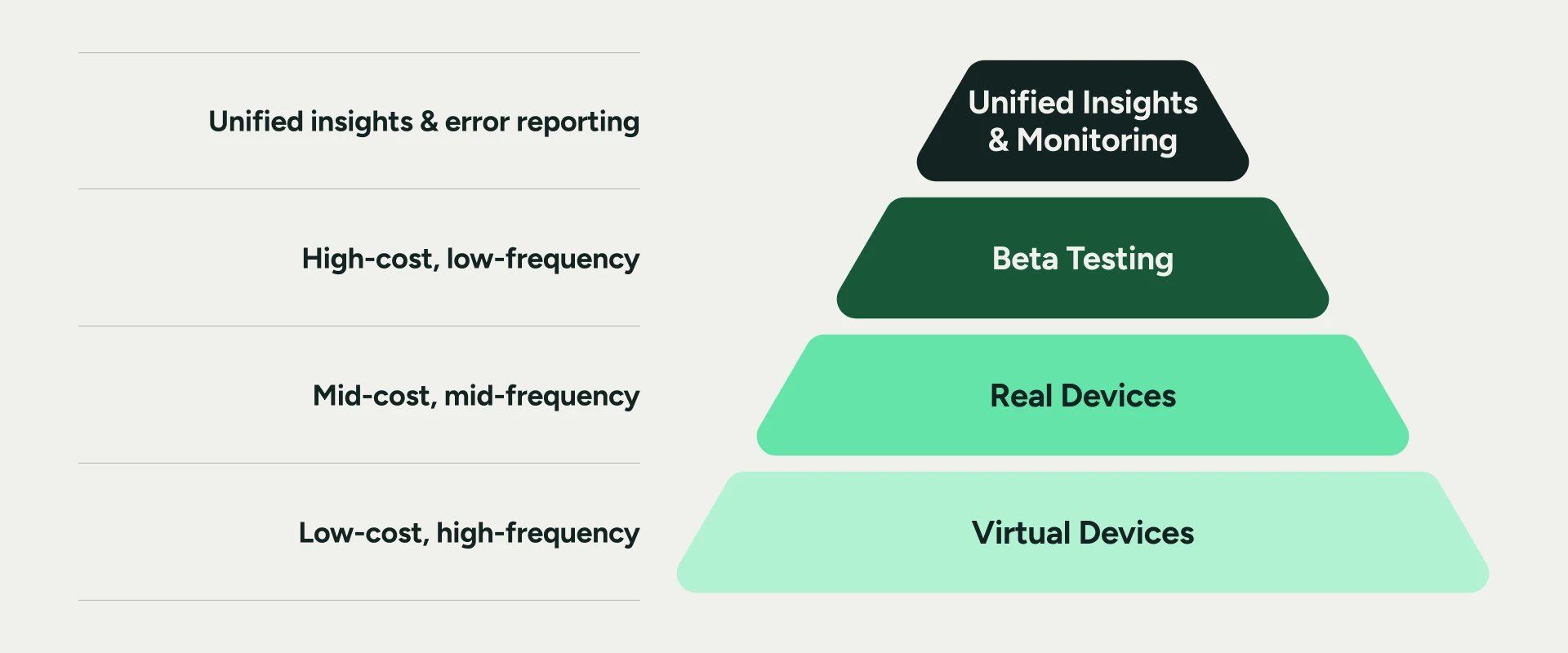
Crowning all of it is unified insights, the feedback loop that connects releases back to production telemetry in real time. The goal is truly knowing where something failed in production and compressing mean time to detection and remediation before a single user has a bad experience.
What mobile release confidence looks like in practice
Real-device coverage has historically meant a painful choice: Buy and maintain a device lab, or accept the coverage gaps that come with emulators and simulators. Neither option scales well when Android and iOS are pushing OS updates on a near-continuous basis and your user base is fragmented across dozens of device models and screen sizes.
Running tests in parallel across hundreds of real devices simultaneously changes that calculus entirely. Every completed run surfaces not just pass/fail status but video playback, network request logs, and device vitals — CPU load, memory pressure, UI responsiveness — across each device in the matrix. The question shifts from “did the feature work?” to “how did this feature perform on a mid-tier Android device running the latest OS under real network conditions?” The answer provides a meaningfully different signal that reliably captures the issues emulators miss.
The harder workflow problem is what happens when something fails. Context-switching between an IDE, a device lab interface, a log aggregator, and an error/crash reporting tool is where debugging time inevitably disappears. Embedding device access directly into the development environment — where a remote real device behaves as if it’s physically connected to the machine — tightens that debugging loop. Developers can set breakpoints and step through code line by line, watching the app react in real time without ever leaving the tools they’re already working on. For teams serious about shifting left, time savings actually accumulate with Sauce Labs embedded directly in the dev environment.
The most forward-looking capability demonstrated was deep, device-level control for AI/agent-ready workflows with programmable mobile cloud. In addition, with AI agents that make insights actionable, developers can query results in natural language — pulling failure context, root cause signals, and recommended fixes directly into their workspace. It's a preview of what agentic testing infrastructure looks like when it's actually connected to the development workflow, not bolted on afterward.
Critically, autonomous analysis surfaces the signal while engineers review and approve remediation to manage compliance, risk tolerance, and release accountability.
The business case behind the infrastructure
To help teams evaluate whether this level of investment is justified, Ashwini closed the session with the numbers. Enterprises that have moved to the full Sauce Labs platform have reported 2.6x savings on infrastructure and operations, defect detection rates before release rising to 95%, production incidents dropping 4x, and developers recovering 90% of debugging time through AI-driven diagnostic insights.
For any organization with revenue-critical mobile apps, a 95% pre-release defect catch rate is a direct risk reduction number with a balance-sheet consequence.
The underlying shift reframes how device infrastructure is classified: not a cost center that teams manage around but a scalable asset that the pipeline runs on. That distinction matters more as AI-native development becomes the norm and the volume of code generated outpaces what any manually managed device lab can keep up with.
Speed and quality have long been positioned as a trade-off. The teams moving past that framing treat their testing infrastructure as a strategic investment, not a liability to minimize.
Watch the full webinar recording or book a demo to see how Sauce Labs can support your team’s mobile release confidence.
