
Software teams face a deceptively simple problem: Unit tests pass, the code looks clean, and then a user hits a workflow that spans three services, two APIs, and a payment processor — and everything falls apart. End-to-end (E2E) testing exists to catch exactly that.
It’s the discipline of verifying that an application performs as designed from start to finish, validating the complete journey a real user takes through your system.
Modern software is no longer a single application running in isolation. Today’s applications involve a sprawling ecosystem of microservices, third-party integrations, cloud databases, and frontend frameworks. Unit tests verify that each piece works in isolation, but they were never designed to guarantee that all those pieces work together correctly.
End-to-end testing gives teams a reliable way to verify system behavior from the user’s perspective, ensuring that real-world workflows function correctly across every integrated component. Done well, E2E tests become the automated safety net that catches what everything else misses.
What is end-to-end testing?
End-to-end testing is a way to test software that validates the full system, including the user interface, backend systems, and its interactions with external interfaces like databases, networks, APIs, and third-party services. Rather than isolating a function or module, it simulates real-world user behavior — logging in, clicking buttons, entering data, waiting for responses, etc. — and then confirms that the system met the user’s expectations at each step.
For example, an E2E test for an e-commerce application might:

Log in as a user
Search for a product
Add it to a cart
Complete checkout
Verify order confirmation and backend transaction success
In the testing pyramid, end-to-end tests sit at the top. There should be fewer of them than unit or integration tests, but each one carries significantly more weight. A single well-designed E2E test can validate dozens of interactions and integrations simultaneously. They are expensive to build, slower to run, and more sensitive to environmental changes than lower-level tests, which is precisely why they should be reserved for the flows that matter most. E2E tests function as the final automated gate before user acceptance testing (UAT) and production deployment.
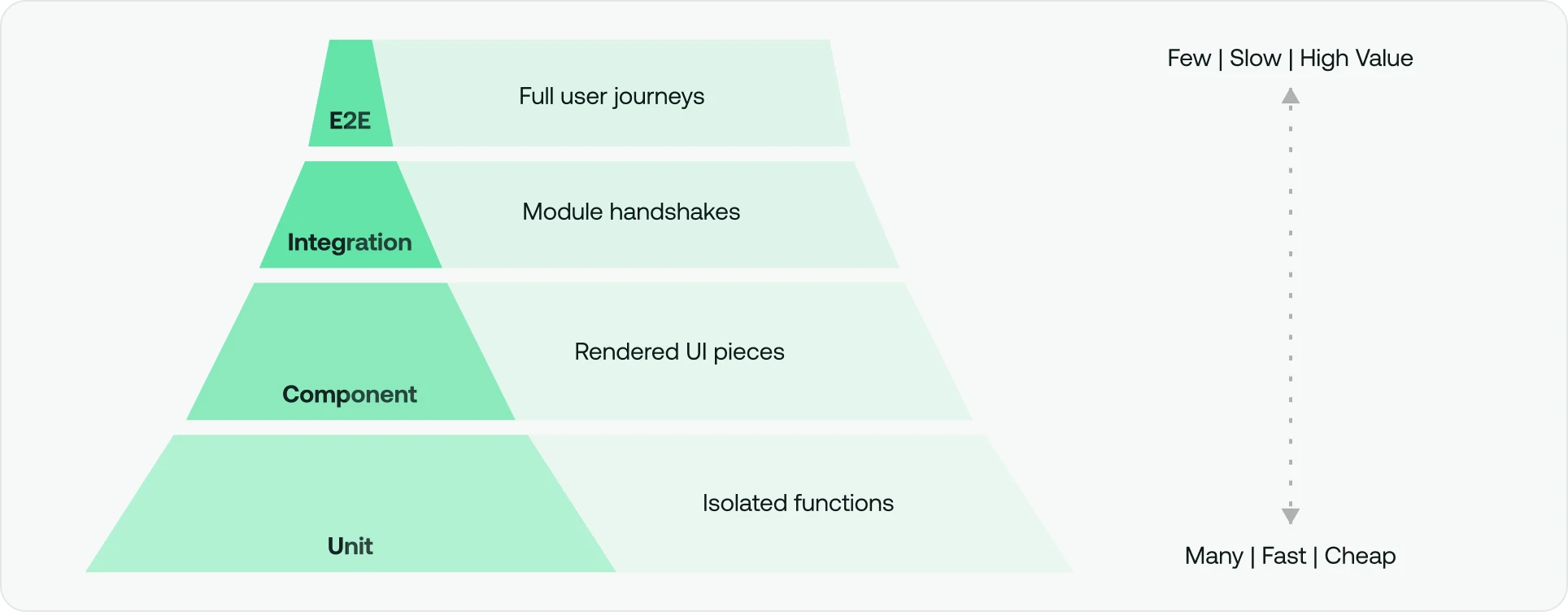
Where unit testing isolates code, E2E testing covers the entire system. Data integrity as it flows between components is a core concern: Does the order placed in the UI actually commit to the database? Does the frontend reflect the change? Does the inventory decrement? Does the confirmation email fire? Those questions require full-system verification to answer with confidence.
Why end-to-end testing matters
The value of E2E testing comes down to one word: confidence. When a product team is about to release a major update, the question everyone is asking is “Will this break anything for users?” Unit tests give you a partial answer, but end-to-end tests give you a thorough one.
Ensuring system health. Applications behave differently when all their components run together versus when they run in isolation. E2E tests catch bugs that only surface when the entire system is under load — race conditions, expired SSL certificates, session handling issues, data transformation errors between services, etc.
Backend and dependency validation. It is not enough to know that an API endpoint accepts a payload. E2E tests verify that database transactions commit correctly, that external APIs return the expected output under realistic conditions, and that the system handles edge cases gracefully.
Confidence in releases. When a critical business workflow passes an E2E test suite, development and QA teams can merge and deploy with far greater certainty. That confidence reduces release anxiety and accelerates shipping cadence.
Reduced cost of failure. A production bug in a checkout flow costs far more than the time spent writing the test that would have caught it — in revenue, customer trust, brand reputation, and engineering time spent on incident response. E2E testing moves the cost of finding bugs before they reach users.
While the benefits of system-wide verification are clear, many engineering teams continue to struggle with differentiating these high-level journeys from the more granular checks performed during integration phases.
End-to-end testing vs. integration testing
While frequently conflated, integration testing and E2E testing answer different questions and operate at different levels of the stack.
Integration testing focuses on the “handshake” between two modules, ensuring a specific service can read from a specific database, for example. It answers the question “Do these components work together?”
End-to-end testing, on the other hand, is concerned with the outcome of a full user journey: “Can the user successfully complete a purchase, from browsing a product to receiving a confirmation email?”
Feature | Integration testing | End-to-end testing |
Scope | Individual software modules or service interfaces | Entire system and user journeys |
Environment | Often mocked or partially virtualized | Production-like staging/QA environment |
Execution speed | Relatively fast and lightweight | Slower (minutes to hours at scale) |
Primary goal | Verify interface and contract correctness | Verify user experience and business logic flows |
Maintenance cost | Lower | Higher |
Integration tests catch interface-level regressions quickly and cheaply, while E2E tests validate that the whole experience holds together. Both are necessary, but treating them as substitutes for one another is how critical bugs slip through.
Once the boundaries between these testing types are firmly established, the next challenge involves mapping out the repeatable steps required to move a test from its initial design to a final, actionable report.
The end-to-end testing lifecycle

A scalable end-to-end testing program follows a structured lifecycle that ensures consistency and reliability.
Step 1: Test planning and design
Before writing a single line of test code, you have to define what “success” looks like. And it often begins with identifying critical user paths and test scenarios based on business impact.
You cannot (and should not) test every possible permutation of your application. Instead, focus on the happy paths and critical business transactions, such as user login and authentication, product search and discovery, and the checkout process. Define scenarios based on real-world usage patterns and technical specifications.
When deciding what to test and why, selectivity is a feature, not a compromise.
Step 2: Environment setup
The integrity of your test results depends on a staging or QA environment that mirrors production: the same hardware specifications, similar network conditions, and identical software versions for all microservices. Without environment parity, tests are prone to false negatives or, even worse, false positives.
Step 3: Test data management
Data management is the silent killer of E2E suites. You must decide between generating fresh test data per run (ideal for determinism) or maintaining a curated static seed. Fresh data prevents test contamination and enables parallelism. Whatever strategy you choose, data cleanup after each run helps avoid state bleed between tests.
Step 4: Test execution
Each test should be independent and able to run in any order, but organize them by feature, user journey, or risk tier, and version control everything.
During execution, run tests via automation tools across a matrix of browsers, operating systems, and device models to surface compatibility issues. Automation tools play a crucial role in running end-to-end tests by streamlining the testing process and executing tests more quickly. Manual execution has its place for exploratory scenarios, but the regression suite should be fully automated and integrated into CI/CD.
Step 5: Results analysis and reporting
Distinguish between genuine application bugs and flaky infrastructure or timing issues before filing defects. Every failure report should include logs, screenshots, and video recordings to give QA the context the team needs to reproduce and fix issues without guessing.
Devs should monitor pass rates, flakiness scores, and execution duration across builds over time and route failures to the right people with enough context to act.
Step 6: Maintenance and iteration
E2E tests are a living asset, not a one-time artifact. A failing test that’s ignored is worse than no test. Consequently, teams need to quarantine flaky tests, refactor as the UI evolves, review coverage as features are added or removed, and track bugs caught by E2E tests vs. bugs that escaped to production to justify and guide investment. From there, consider entering an ongoing cycle of updating tests to match new UI changes or updated business logic, continuously improving end-to-end tests.
Navigating the technical lifecycle provides the necessary foundation, but scaling these efforts across a growing enterprise requires a more deliberate, long-term strategic approach to resource allocation.
Creating an end-to-end testing strategy
A scalable E2E strategy focuses on precision, not volume.
Prioritize critical workflows. E2E tests carry real maintenance overhead. Rather than automating every possible flow, focus on the 20% of user journeys that account for 80% of usage or revenue — the critical business transactions, flows where a bug would have direct, measurable impact. Everything else can likely be covered by unit tests or exploratory manual testing.
Manage test data rigorously. Shared state between tests is the enemy of both reliability and parallel execution. Each test should own its data lifecycle: create what it needs, run, and clean up. Since “ghost” data in the system means subsequent runs will eventually fail, test data management pays dividends in both test speed and flakiness reduction.
Handle external dependencies deliberately. Decide, for each third-party service, whether to use its sandbox mode or mock it entirely. Real service calls add latency and introduce failure modes outside your control. Mock them for speed-sensitive flows, and use real sandboxes when the integration behavior itself is under test to keep your pipeline moving.
Integrate with CI/CD at multiple gates. A smoke suite covering the most critical paths should run on every pull request. The full regression suite is better suited to nightly builds or pre-release pipelines, where longer execution times are acceptable in exchange for comprehensive coverage.
A robust strategy is only as effective as the execution method chosen for each specific scenario, which brings us to the critical balance between human intuition and the raw speed of machine automation.
Manual vs. automated end-to-end testing

Both approaches play important roles in a complete testing strategy. Manual testing remains essential for scenarios where human judgment is irreplaceable, whereas automated testing drives modern DevOps, allowing teams to execute hundreds of tests in parallel and providing coverage that would be humanly impossible within the time constraints of a modern sprint.
Scenario | Manual approach | Automated approach | Verdict |
UX and visual design review | Human eye | Pixel matching or visual diffs | Manual or shift-left visual testing |
Repetitive regression on stable flows | Slow, time-consuming, error-prone over time | Fast, consistent, scalable, highly efficient | Automate |
Complex edge cases with ambitious logic | Better for exploration | Can be brittle without good data strategy | Mixed approach |
High-volume data entry across many users | Error-prone, not feasible at scale | Essential | Automate |
Deciding when to automate represents half the battle, while the other half involves selecting the specific software frameworks that will power those automated scripts across a fragmented landscape.
Choosing the right foundation for end-to-end testing
The E2E tooling ecosystem is mature, but the choice of framework matters less than how well it integrates with the rest of your testing infrastructure. The questions worth asking are not “Which framework is most popular?” but rather:
Does it support the browsers and devices your users actually run?
Can it scale across parallel workers without significant configuration overhead?
Will it hold up inside a CI/CD pipeline running dozens of builds a day?
What separates teams that run E2E tests from teams that run them reliably at scale is infrastructure. Sauce Labs provides:
A framework-agnostic cloud platform purpose-built to run E2E tests
Scalable cloud environments
Access to real devices and browsers
Parallel execution across global infrastructure
The platform allows teams to run large E2E suites efficiently without the overhead of managing that infrastructure in-house. The right framework gets tests written, but the right infrastructure keeps them running.
Maintaining that momentum requires adhering to rigorous industry standards that prevent technical debt and ensure script longevity.
Best practices for efficient end-to-end testing
Make tests atomic. Each test should run independently. Failures should not cascade across tests.
Use stable selectors. Avoid brittle selectors tied to UI structure. Instead, use attributes like data-testid.
Handle asynchronous behavior. Replace hard-coded delays with intelligent waits based on application state.
Run tests in parallel. With proper data isolation, tests can execute concurrently across multiple workers or machines, compressing hours of serial execution into minutes.
Maintain test code. Refactor shared logic into reusable components. Treat test code with the same discipline as production code.
Even with a perfectly architected suite and the best tools at your disposal, environmental variables and complex application logic will inevitably introduce hurdles.
Challenges of end-to-end testing and how to solve them
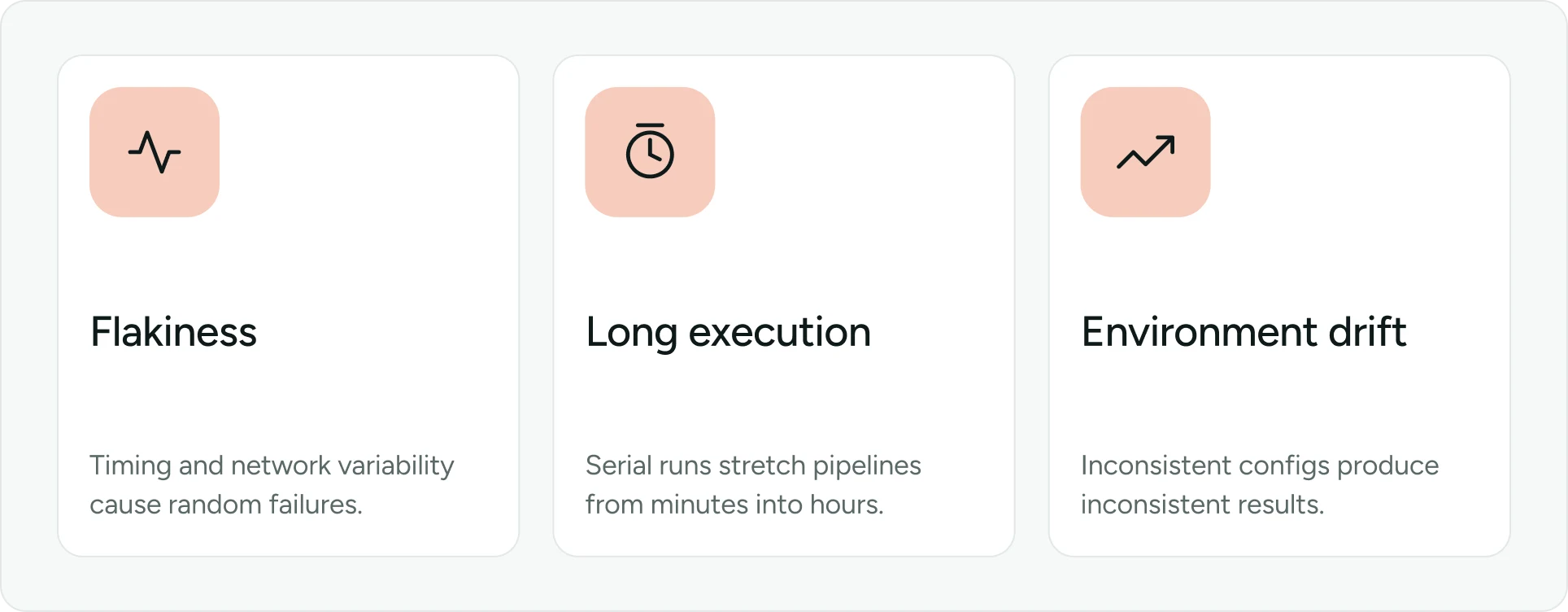
Common challenges include:
Flakiness caused by timing and network variability
Long execution times slowing pipelines
Environment drift creating inconsistent results
Solutions focus on stability, parallelization, smarter selectors, and environment consistency.
Symptom | Likely cause | Investigation step | Fix |
Random failures | Timing issue or network flakiness | Check for hard-coded waits or external API calls | Add explicit waits; mock unstable dependencies |
Fails only in CI | Environment differences | Compare local vs CI configs | Align environments or use containers |
Element not found | UI changes | Inspect DOM changes | Use data-testid |
Timeout errors | Slow APIs or network | Review HAR file and network trace | Optimize backend or increase timeout thresholds |
Attempting to solve these systemic issues on local infrastructure or limited emulators is often a losing battle, which is why modern enterprise teams move their execution to specialized cloud-based testing platforms designed for massive scale.
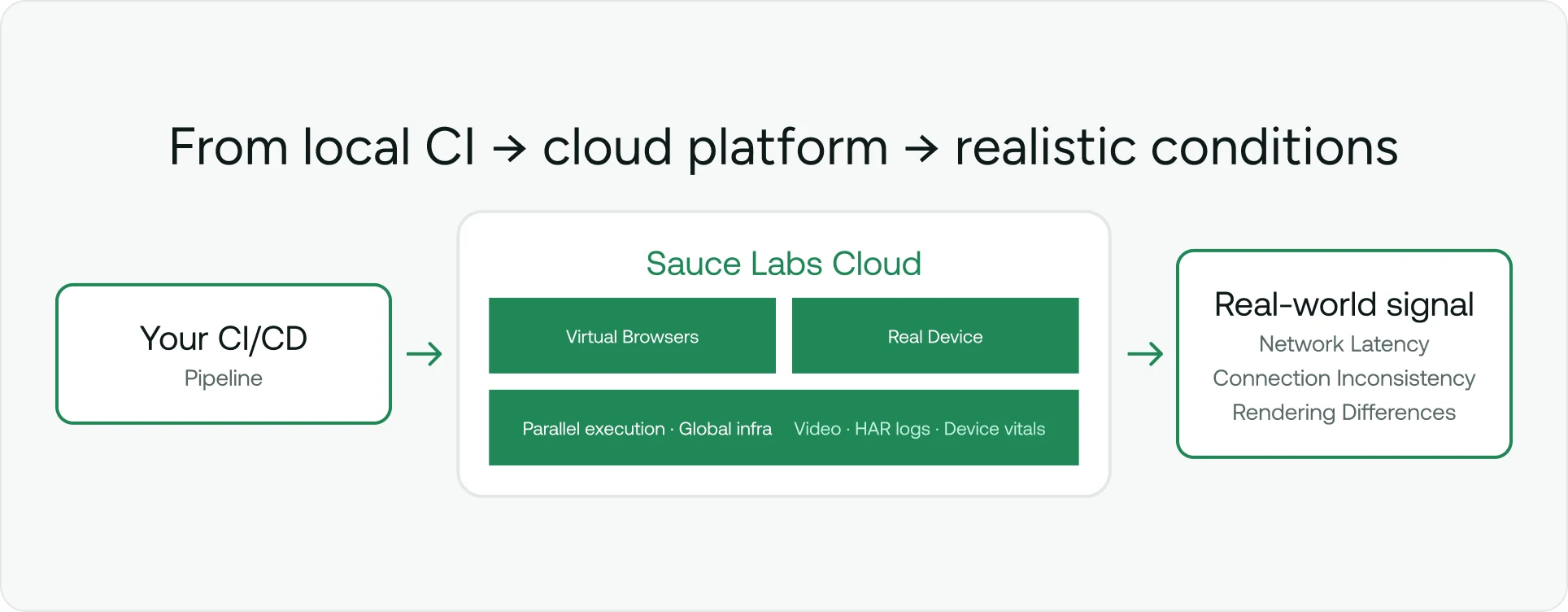
Sauce Labs empowers teams to move beyond the limitations of local testing. The moment a test runs against a virtual browser or real device across the public internet — rather than a mocked environment on a developer’s machine — the application already encounters the kind of variability your actual users experience. Network latency, connection inconsistency, and rendering differences across hardware generations are the conditions under which your software will be judged.
A realistic performance signal, at scale
Whether running against virtual browsers or physical devices, tests executed on Sauce Labs operate across real network infrastructure. That distinction matters because hermetic local testing, however tightly controlled, cannot reproduce the performance signal that comes from exercising an application the way users do. Teams get accurate data on how their application behaves under realistic conditions — not how it behaves in an idealized local environment — which is a fundamentally different and more actionable kind of confidence. Pair that with access to thousands of real device and browser combinations spanning OS versions, screen sizes, and hardware generations, and the gap between “tests pass in CI” and “works for our users” narrows considerably.
Comprehensive debugging
When a test fails in the cloud, root cause analysis requires more than a stack trace. With Sauce Labs, you can access detailed diagnostics:
Video recordings
Network logs (HAR files)
Device vitals
These insights give engineers the full diagnostic picture they need, accelerating failure analysis and reducing mean time to resolution.
Visual regression testing
Validate not only functionality but also UI consistency across releases.
Orchestration
With Sauce Labs, teams can run tests directly from their repositories, reducing overhead and improving execution efficiency.
Centralizing verification efforts on a platform built to handle the complexities of the modern web transforms testing from a necessary development hurdle into a strategic driver of software excellence.
Get started with Sauce Labs today
While end-to-end testing is resource-intensive, it is the only way to guarantee the seamless experience your users demand. By automating your critical paths and running them on a robust cloud infrastructure, you can turn testing from a bottleneck into a competitive advantage.
Start building a scalable end-to-end testing program today with a free Sauce Labs trial.
