In order for Selenium or Appium to click on an element, type into it, or mouse in or out, the tool first needs to find the element. The WebDriver code library provides methods to do just that, such as findelement() or findelements(). These usually take a locator, which can be created by ID, XPATH Code, or Cascading Style Sheets (CSS). Getting the XPATH code can be as easy as selecting the element in developer tools or using something like Chropath. Fundamentally, XPATH is a query language for XML-like documents, such as web pages. It can be awkward to write, brittle, and even more awkward to reverse engineer. As a result, CSS has gained favor as the way to identify objects in WebDriver.
Like most powerful things, CSS has a bit of a learning curve. It's certainly a lot more challenging than cutting and pasting from a tool. Yet if you invest the time in learning CSS Selectors, you can have more powerful bindings that are easier to read, less brittle, and slightly more closely integrated into the browser platform.
Today we'll provide CSS rules, tips, and pseudo-classes to either get you out on the right foot, or, perhaps help you move your XPATH locators to CSS.
Getting Started with CSS Selectors
A CSS Selector is a combination of an element selector and a value which identifies the web element within a web page. They are string representations of HTML tags, attributes, Id and Class. As such they are patterns that match against elements in a tree and are one of several technologies that can be used to select nodes in an XML document.
Today we'll cover simple CSS selectors, then more advanced, then pseudo-classes, which are essentially powerful, built-in matching functions that reduce a search to just what you are looking for.
I: Simple
Id
An element’s id in XPATH is defined using: “[@id='example']” and in CSS using: “#” - ID's must be unique within the DOM.
Examples:
1XPath: //div[@id='example']2CSS: #example
Element Type
The previous example showed //div in the xpath. That is the element type, which could be input for a text box or button, img for an image, or "a" for a link.
1Xpath: //input or2Css: =input
Direct Child
HTML pages are structured like XML, with children nested inside of parents. If you can locate, for example, the first link within a div, you can construct a string to reach it. A direct child in XPATH is defined by the use of a “/“, while on CSS, it’s defined using “>”.
Examples:
1XPath: //div/a2CSS: div > a
Child or Sub-Child
Writing nested divs can get tiring - and result in code that is brittle. Sometimes you expect the code to change, or want to skip layers. If an element could be inside another or one of its children, it’s defined in XPATH using “//” and in CSS just by a whitespace.
Examples:
1XPath: //div//a2CSS: div a
Class
For classes, things are pretty similar in XPATH: “[@class='example']” while in CSS it’s just “.”
Examples:
1XPath: //div[@class='example']2CSS: .example
II: Advanced
Next Sibling
This is useful for navigating lists of elements, such as forms or ul items. The next sibling will tell selenium to find the next adjacent element on the page that’s inside the same parent. Let’s show an example using a form to select the field after username.
1<form class = "form-signin" role = "form" action = "/index.php" method = "post">2<h4 class = "form-signin-heading"></h4>3<input type = "text" class = "form-control" id = "username" name = "username" placeholder = "username" required autofocus></br>4<input type = "password" class = "form-control" id = "password" name = "password" placeholder = "password" required>5<p>6<button class = "btn btn-lg btn-primary btn-block radius" type = "submit" name = "login">Login</button>7</form>
Let’s write an XPath and css selector that will choose the input field after “username”. This will select the “alias” input, or will select a different element if the form is reordered.
1XPATH: //input[@id='username']/following-sibling:input[1]2CSS: #username + input
Attribute Values
If you don’t care about the ordering of child elements, you can use an attribute selector in selenium to choose elements based on any attribute value. A good example would be choosing the ‘username’ element of the form above without adding a class.
We can easily select the username element without adding a class or an id to the element.
1XPATH: //input[@name='username']2CSS: input[name='username']
We can even chain filters to be more specific with our selectors.
1XPATH: //input[@name='login'and @type='submit']2CSS: input[name='login'][type='submit']
Here Selenium will act on the input field with name="login" and type="submit"
Choosing a Specific Match
CSS selectors in Selenium allow us to navigate lists with more finesse than the above methods. If we have a ul and we want to select its fourth li element without regard to any other elements, we should use nth-child or nth-of-type. Nth-child is a pseudo-class. In straight CSS, that allows you to override behavior of certain elements; we can also use it to select those elements.
1<ul id = "recordlist">2<li>Cat</li>3<li>Dog</li>4<li>Car</li>5<li>Goat</li>6</ul>
If we want to select the fourth li element (Goat) in this list, we can use the nth-of-type, which will find the fourth li in the list. Notice the two colons, a recent change to how CSS identifies pseudo-classes.
1CSS: #recordlist li::nth-of-type(4)
On the other hand, if we want to get the fourth element only if it is a li element, we can use a filtered nth-child which will select (Car) in this case.
1CSS: #recordlist li::nth-child(4)
Note, if you don’t specify a child type for nth-child it will allow you to select the fourth child without regard to type. This may be useful in testing css layout in selenium.
1CSS: #recordlist *::nth-child(4)
In XPATH this would be similar to using [4].
Sub-String Matches
CSS in Selenium has an interesting feature of allowing partial string matches using ^=, $=, or *=. I’ll define them, then show an example of each:
1^= Match a prefix2CSS: a[id^='id_prefix_']34A link with an “id” that starts with the text “id_prefix_”56$= Match a suffix7CSS: a[id$='_id_sufix']89A link with an “id” that ends with the text “_id_sufix”1011*= Match a substring12CSS: a[id*='id_pattern']1314A link with an “id” that contains the text “id_pattern”15
Pseudo Class Compatibility
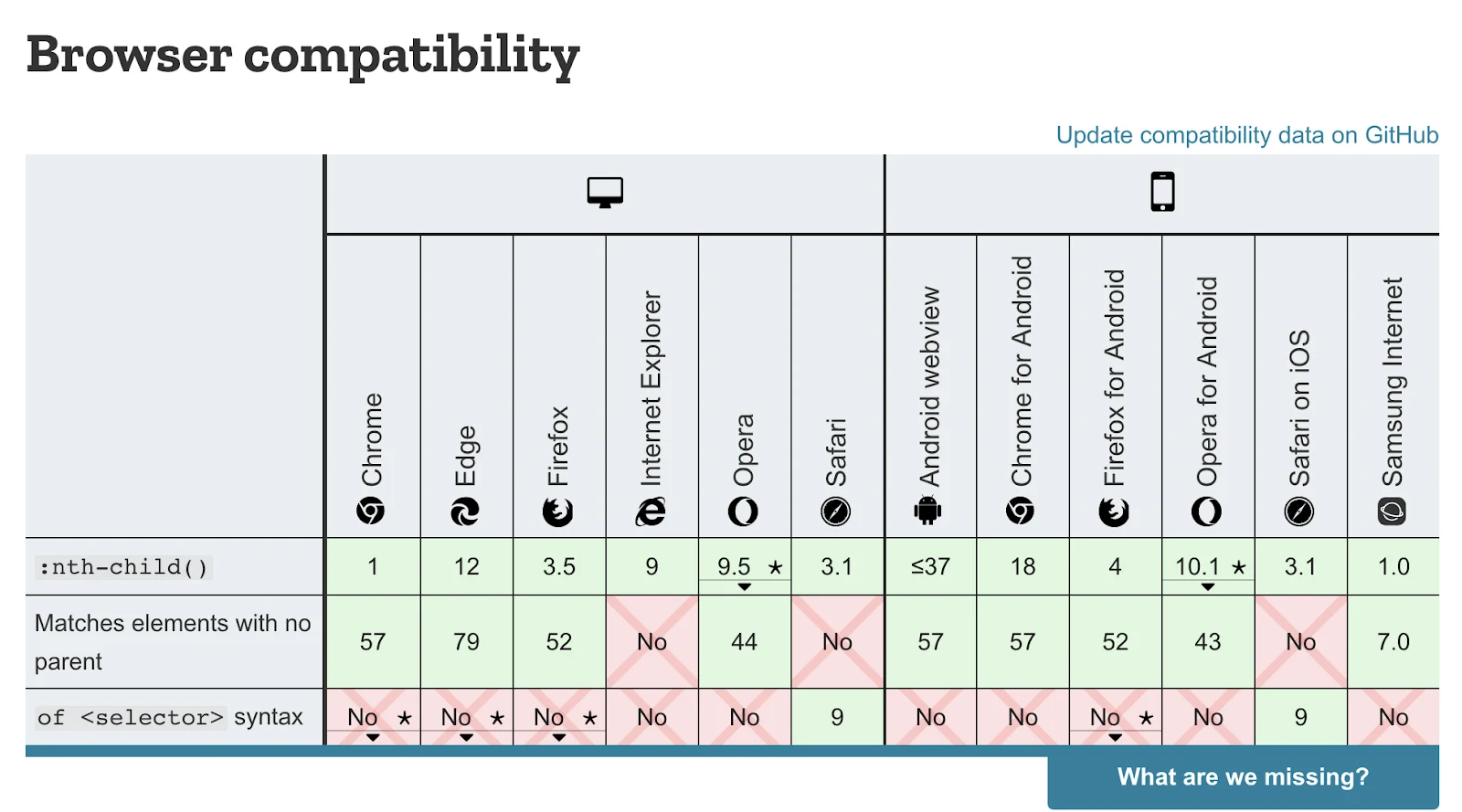
An earlier version of this article references :contains, a powerful way to match elements that had a desired inner text block. Sadly, that feature is deprecated and not supported any longer by the W3C Standard. The current CSS Selectors level 3 standard is implemented by all major browsers; level 4 is in working draft mode. That standard document has a detailed list of selectors and pseudo-classes. For a more manageable list, look at the Mozilla Documentation which has a wonderful, complete list of psuedo classes. Drill into any pseudo-class and scroll down for specific information on compatibility in different browsers, including this example from the nth-child() pseudo-class.