
In software engineering, a design pattern is a general reusable solution to a commonly occurring problem in software design. A design pattern is not a finished design that can be transformed directly into code. It is a description or template for how to solve a problem that can be used in many different situations.(("Software design pattern - Wikipedia, the free encyclopedia" 2011. 18 Jan. 2016)) Why are design patterns so important for Selenium development? It can speed up development and reduce the maintenance impact. Using design patterns in test automation development is not necessary, but a seasoned automation engineer understands the importance. If you are new to test automation, I highly recommend learning the best way to write automated tests, and this article is a great start.
Organization of Tests (The Structure)
Don’t make it complicated. Keep it simple and clear when setting up an organized folder structure for tests and reusable page objects. Start with a clean and well-planned folder structure for new and existing team members to understand. Here is a simple and complex folder structure for Cucumber. [table id=9 /] If the test structure starts to get too disorganized or confusing, never be afraid to refactor. It is an incredible opportunity to rebuild your folder structure by moving files around the way you’d like. Here are three best practices for the organization of tests:
Create a “template” script for an empty subfolder structure and the files needed for new development
Avoid ambiguous and potentially redundant folders by using IDE (RubyMine) and creating reusable page objects.
Naming convention for folder and files using keywords related to the feature
Don’t Repeat Yourself (DRY)
This principle is so important to understand. The premise — eliminating the need to duplicate code anywhere within your suite of tests. It seems so obvious. Why would anyone want to copy and paste code? The duplication of code is surprisingly a common problem among software and automation development. It mainly comes from beginner-level programmers. Why is code duplication so very bad? Because it’s a maintenance nightmare. The first test automation project I ever worked on had 40+ non-programmers converting manual tests to automated tests. To keep the story short, they were copying and pasting code EVERYWHERE. What’s the problem with that? Your test breaks and you need to update your code, then you need to find everywhere else it was copied and update it. Refactor all duplicate code by following the Page Object Model.
Page Objects Model (POM)
The purpose of the Page Object Model is to encapsulate a web page entirely in your application in a single class file. Each page of the application would be mapped to a class file, and each method within the class represents a page object. The object hides multiple technical details about the interaction with the page; for the most part, it creates a reusable object that can be used with any test. It merely helps Selenium code to be more readable, maintainable, and reusable. It is important to keep page objects modular and independent. How would a page object look for a login page? To create a page object, we first need to understand the page to create an abstraction layer of it. Example: Screenshot of Login Page
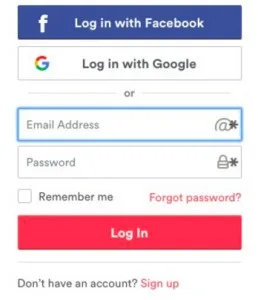
Example: Page Object Code
class LoginPage
include Capybara::DSL
def login(username, password)
find(:id, 'signin_email').set(username)
find(:id, 'signin_password').set(password)
find('.user-login-btn').click
end
def loginWithFacebook
# No unique ID so using text on page to find element
find('.text-container', :text => 'Log in with Facebook').click
end
def loginWithGoogle
# No unique ID so using text on page to find element
find('.text-container', :text => 'Log in with Google').click
end
# Continue additional methods 'Remember Me', 'Forgot password', etc
end
Example: Usage of the Page Object inside test
login_page.login('gsypolt', 'password1234')
Locator Strategy
I agree with @TourDeDave — Locators are the lifeblood of your Selenium tests. The Selenium web driver uses locators to find the elements on web pages. The most efficient way (and preferred way) to locate an element on a web page is to use unique IDs. When there is no ID to use, the next preferred choices are NAME and CSS locators. The only problem with using NAME and CSS locators is that sometimes a page may contain multiple elements with the same name. Why is this a problem? It’s a problem because Selenium is designed to find the first matching element on the page. To find the second or third element on the page, many need to use one of the other types of locators: Link Text, Partial Link Text, Tag Name, Class Name, Attributes, Datasets, and XPATH. The XPATH locator should only be used as the last resort to find an element on web pages. The key is to have a clear locator strategy with developers. The conversation outlines your preferred locator for automated tests and the importance of creating unique locators. Resource:
How to Verify Your Locators Without Selenium by Dave Haeffner
Choosing a Locator Strategy by Dave Haeffner
Design for Scalability
Selenium tests should be built to scale. Growing from small to an abundance of tests happens so quickly. The execution time increases and starts to hold up releases until all the tests complete. Executing hundreds of tests requires a bit more planning and design from the beginning. Don't think about scale last, and then be in the world of technical debut and refactoring. Don’t be that company. Join the elite by thinking about design from the beginning. Three Important Points for Scaling Test Automation
It starts by developing automated tests to be small and modular (independent), which allows for faster feedback
Continuous Integration (eliminate the human factor from the equation)
Ability to run hundreds of tests in parallel (check out my blog post to learn about ‘The Benefits of Parallel Testing’.)
Conclusion
To get the most out of your test automation projects, good processes and design patterns should be in place. The elite companies dedicate an experienced automation expert to think about infrastructure first and oversee all types of automation development. Greg Sypolt (@gregsypolt) is a senior engineer at Gannett and co-founder of Quality Element. He is a passionate automation engineer seeking to optimize software development quality, while coaching team members on how to write great automation scripts and helping the testing community become better testers. Greg has spent most of his career working on software quality — concentrating on web browsers, APIs, and mobile. For the past five years, he has focused on the creation and deployment of automated test strategies, frameworks, tools and platforms.
